

AIでAI作ってみた
こんにちは。ソリューション開発部AI分科会の高地です。
最近AIが仕事を奪うってよく聞くと思います。恐ろしいですよね。
AI分科会では、案件以外でAIに関する技術の勉強や習得に取り組んで、AIに仕事を奪われないように模索しています。
そんな分科会の活動の一環として、生成AIを開発の道具としてどう使えるかを考えるために、犬か猫かを見分ける小さなアプリを、AIコードエディタ「Cursor」と “ペアプロ” 手法でゼロから開発してみました。
目的は、生成AIにすべてを任せて何かを作ることではありません。
AIと一緒に考えながら開発すると、何が楽になって、何が難しくなるのかを試してみることが目的です。
ここでは、AIコーディングに興味がある・使い始めた方、AIに仕事を奪われたくないエンジニアに向けて、モデルの精度や派手な成果よりも、設計やレビュー、試行錯誤の中で「これはAIに任せてよかったな」とか「ここは人間がちゃんと考えないとダメだな」と感じたポイントを振り返ってみます。
なにを作ったの?
犬と猫の画像をアップロードすると、AIがどちらかを判定して確信度を表示するシンプルな Web アプリです。
学習から推論、フロントまで、最小構成で「アップロード→判定→表示」の流れを通しました。
技術スタック
学習部分(Python)
- PyTorch(機械学習フレームワーク)を使って、画像認識でよく使われる ResNet18 というモデルをベースに学習を進めます。
- PyTorchのライブラリ(torchvision)が提供する、ImageNet(1000種類の画像)で事前に学習済みのResNet18モデルを使っています。このモデルはすでに「画像から特徴を抽出する」能力を持っているので、一から学習する必要がありません。
最後の層だけを2クラス(犬/猫)用に置き換えて、犬と猫の画像データで学習させました。
これにより、少ないデータでも精度が出るようになります(この手法を「転移学習」と呼びます) - 学習データは
training/data/train/{cat,dog}/に配置、検証データはtraining/data/val/{cat,dog}/に配置します。 - 検証精度が上がったタイミングで
training/outputs/models/best.ptに保存します。
推論API(FastAPI)
POST /predictエンドポイントで画像を受け取る(multipart/form-data)- 画像を224×224にリサイズ → ImageNetの正規化を適用 → モデルで推論
- レスポンスは
{label: "cat" or "dog", confidence: 0.0-1.0, inference_ms: 推論時間}のJSON形式 - 起動時に
best.ptをロードして推論に使用
フロント(React + Vite)
- 画像を選択してアップロードするシンプルなUI
- アップロードした画像のプレビュー表示
- 推論結果(ラベルと確信度)をカード形式で表示
- ローディング状態の表示
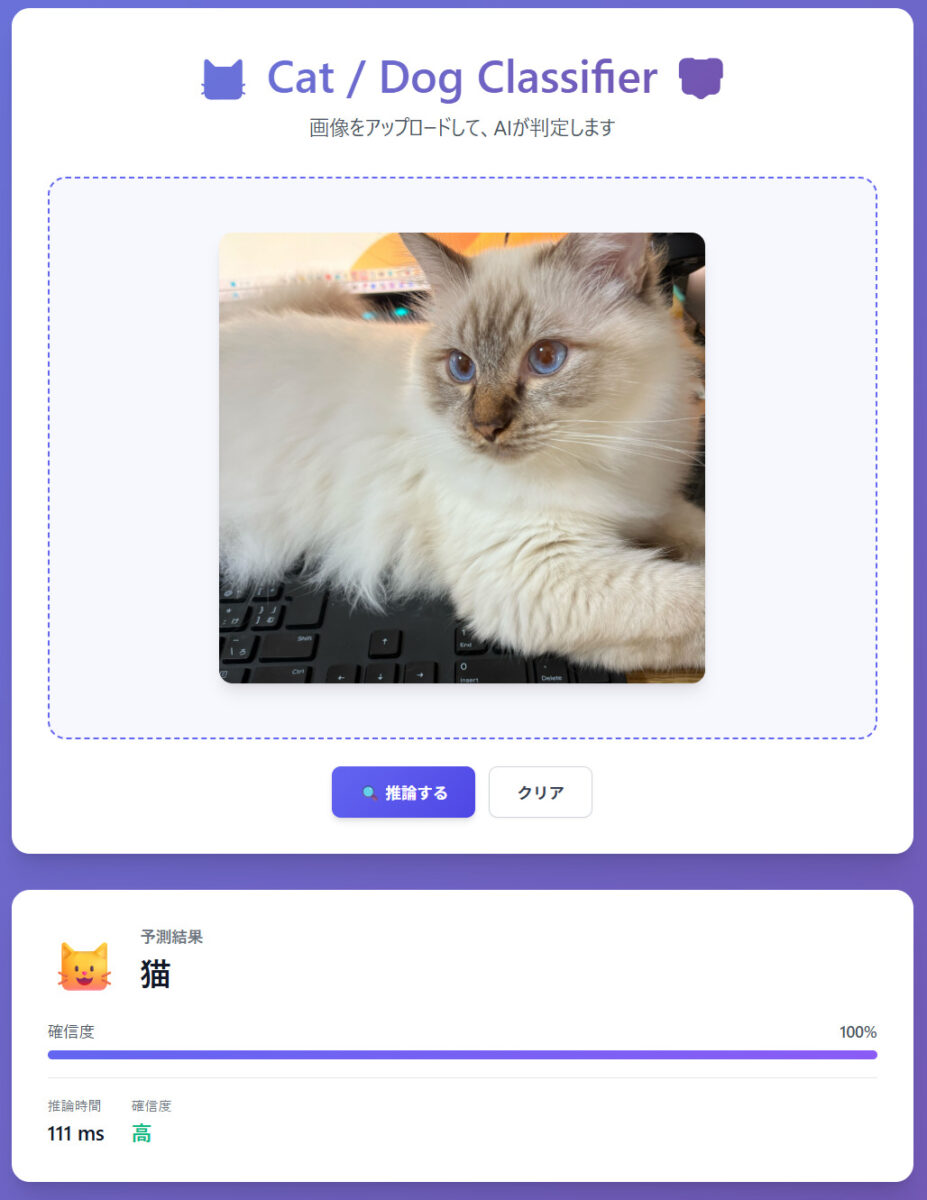
結果(性能指標)
- 検証データでの正答率: 学習データの量や質によって変わりますが、転移学習により少ないデータでもある程度の精度が出ます。
- 今回は 20 枚の学習データで学習させてみました。
- 予測結果は以下の通りで、猫の予測が弱そうでした。
| 正解 \ 予測 | 犬 | 猫 |
| 犬 | 19 | 1 |
| 猫 | 6 | 14 |
- 推論時間は CPU 環境でも 1 枚あたり数十 ms 程度で推論可能です。
- 「確信度」という指標を算出させてみたところ、猫を犬と予測した半分くらいが 60% 前後 (確信度: 低)となっており、間違えた中でも改善の余地はありそうでした。
このアプリを作るのに使ったプロンプト
最初のプロンプト
今回は、いきなりコードを書かせるのではなく、
「どんな構成・設計が適切か」をAIに検討させるところから始めました。
生成AIはコード生成が注目されがちですが、実務ではそれ以前に「設計の妥当性」を考える工程のほうが重要です。
その後、上記の要件で気になるところを少しずつ明確化していきました。
このように、小さく始めて、動かしながら要件を明確化していく流れが、Cursor とのペアプロでうまくいきました。
設計書を書き出して、複数エージェントにレビューさせた
最初の提案を受けて、設計書をmdファイルに書き出しました。
そして、Cursor の複数エージェント機能を使って、この設計書を複数のエージェントにレビューさせて比較してみました。
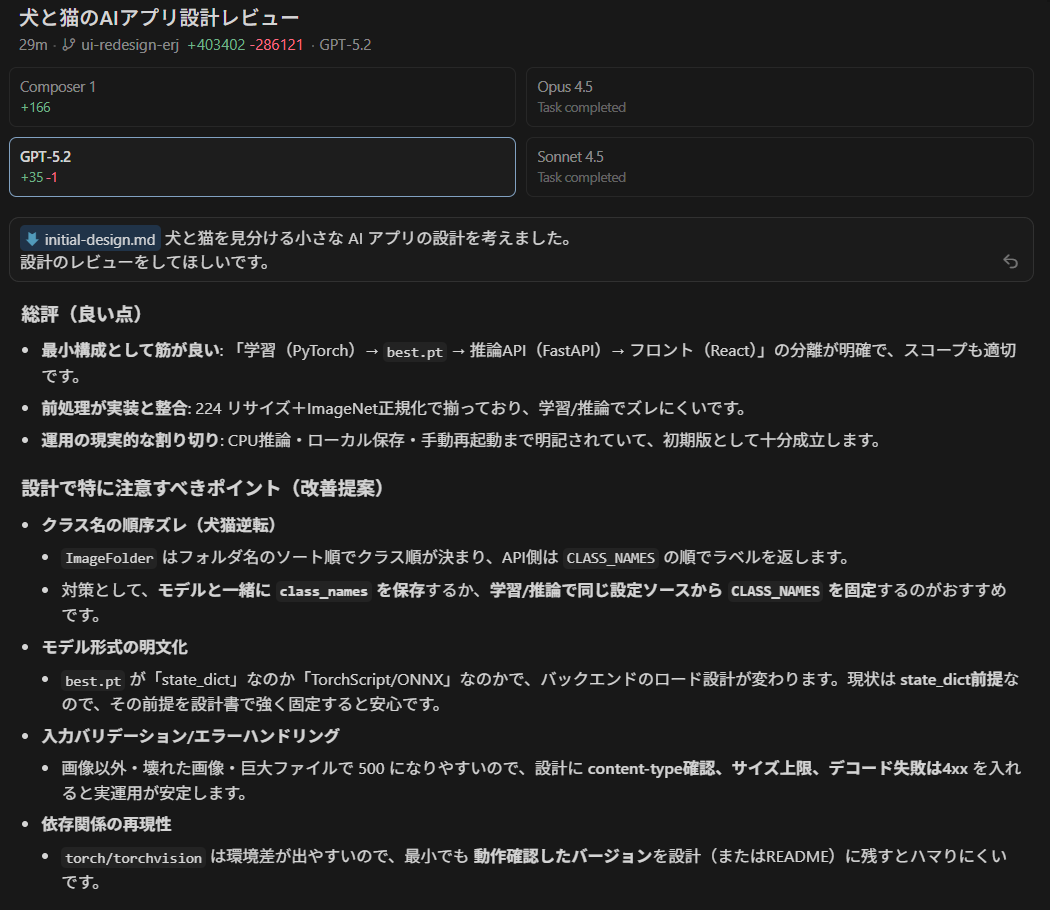
それぞれのエージェントが異なる視点から指摘してくれたので、設計の抜け漏れを発見できました。
複数エージェントにレビューさせることで、1つのエージェントでは見落としがちな視点を拾えました。設計段階でこれができるのは、Cursor の強みだと思います。
開発にかかった時間・コスト
- 開発時間: 約2-3時間
- Cursor使用料: Pro プラン(月額 $20)を使用
- トークン使用量: 正確な数値は記録していませんが、約 20 ファイルの生成と複数回の修正で、数千トークン程度と推測
- 実際のコスト: Cursor Pro の月額料金のみ(従量課金なし)
どんな流れで進めた?
1. 設計書の作成とレビュー
最初のプロンプトで構成案を提案してもらった後、設計書をmdファイルに書き出し
→複数エージェントにレビューさせて、異なる視点からのフィードバックを収集
→設計の抜け漏れを早期に発見し、改善点を反映してからコード生成に進みました。
2. ひな形づくり
設計書レビューで得たフィードバックを反映して、目的と制約を言語化
→ 3層(学習/API/フロント)の最小セットを一気に生成
→約20ファイル以上が一度に生成されました。
3. 動作確認
ダミーのモデルを書き出して、まずは配線が通っているかチェック
→エラーが出たらログをCursorに貼り付けて、原因特定と修正を依頼
→python-multipart の不足など、細かい問題をその場で解決しました。
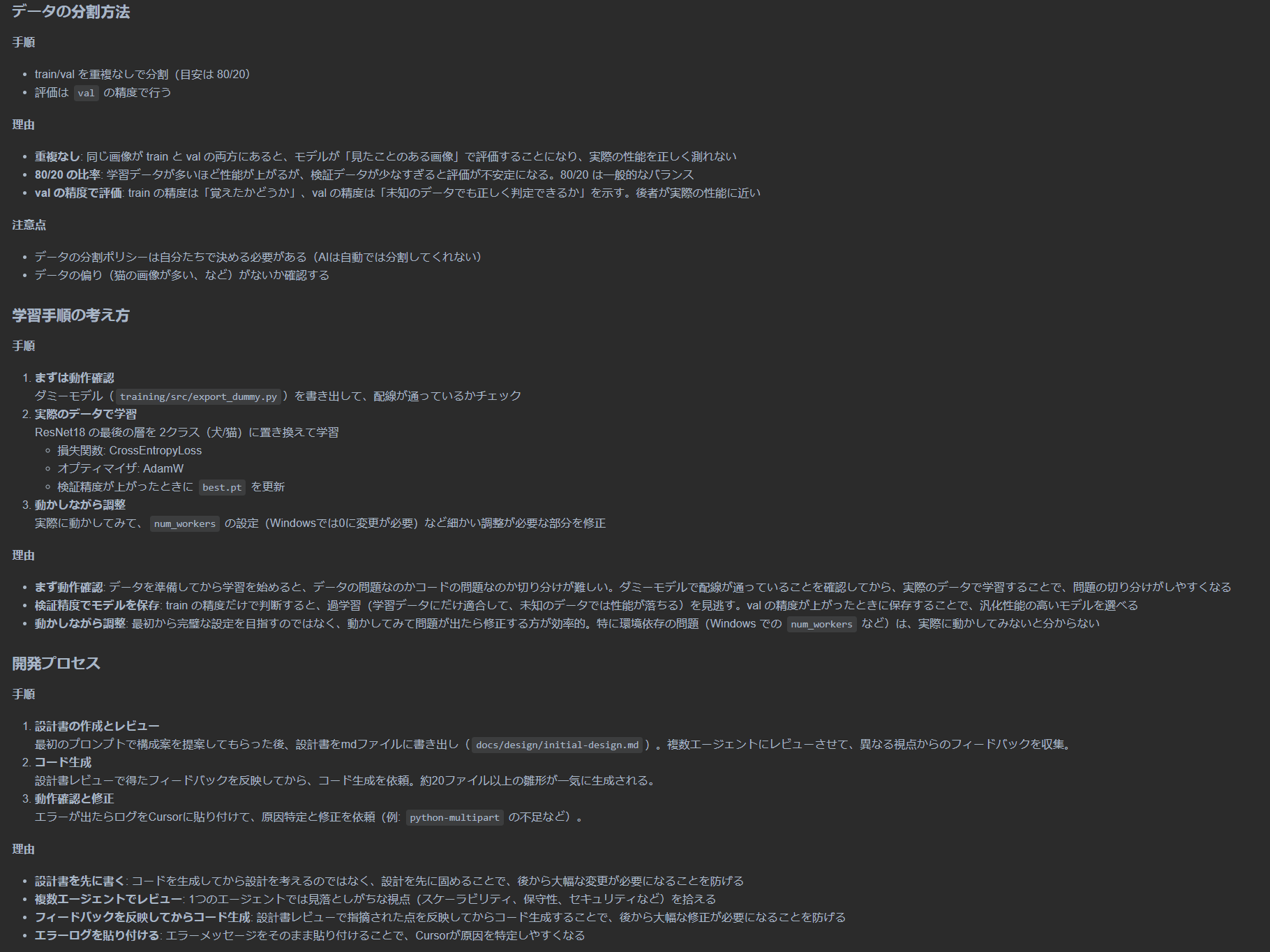
4. データの考え方train/ と val/ を重複なしで分割(目安は 80/20)
→評価は val の精度で
→データの分割ポリシーは自分たちで決め、README に記録しました。
5. 学習と改善
ResNet18 の最後を2クラスに
→CE + AdamW、val 精度が上がったときに best.pt を更新
→実際に動かしてみて、細かい調整が必要な部分を Cursor に修正してもらいました。
6. まわりを整える
→例外(壊れ画像など)、推論時間、CORS、環境変数… “必要なだけ” ゆるく整備
→設計書レビューで指摘された点(エラーハンドリング、環境変数管理など)もここで反映しました。
Cursor、どう使った?——「AIに丸投げしない」を実践
役割分担の考え方
「小さく作って速く回す」サイクルを加速させるために Cursor を使いました。コードを書く時間、エラーを解決する時間を短縮し、試行錯誤のサイクルを速く回す。そのために Cursor に任せられる部分は任せ、判断が必要な部分(データの分割方法、設計の線引き、エージェントの提案の取捨選択など)は自分で決めました。
具体的な使いどころ
- 設計段階での複数エージェントレビュー
- 要件を会話でほぐしつつ、最小構成のひな形を一気に作成
- CORS やエンドポイント設計、依存の抜けもその場でフォロー
- 構文エラーや実行時エラーの一次切り分けを素早く修正
- 手順や分割の考え方は README や RULE に “その都度” メモして、あとからの再現性を確保
- 同一チャット内であれば今までの会話を記録してくれますが、チャットが長くなったりチームで実施しようとするとメモリが引き継がれないため、共通の考え方はどこかに保持しておいた方が良いです。
気をつけたこと
「AIがある程度要望通りに成果物を作ってくれる」という期待で、チャットのアウトプットをしっかり見ないで次に進んでしまうこともありました。しかし、AIはハルシネーション(事実と異なる情報を生成すること)の問題があるので、必ずしも要望通りの成果物になるとは限りません。
特に「動くけど意図と違う動作をする」「一見正しそうだけど実は間違っている」といった「気づきにくい矛盾」は見過ごしがちです。そのため、Cursor が生成したコードや提案も、そのまま信じるのではなく、動作確認したり逆にAIに意図を聞き返して確認したりと確認のフェーズを設けるようにしました。
複数エージェントのレビュー結果も、すべてを採用するのではなく、自分の判断で取捨選択しました。エージェントの意見は参考意見として扱い、最終的な決定は私が行いました。
やってみて良かったこと / つまずき
良かったこと
- プロンプトを投げてから動くコードができるまでの時間が短い
- 最初のプロンプトで構成案を提案してもらい、設計書レビューを経て、コード生成を依頼すると、約 20 ファイル以上のひな形が一気に生成されました。
- 依存関係の設定やディレクトリ構造の作成も含めて、すぐに手を動かせる状態になりました。
- また、複数エージェントで実行することで結果を比較して一番良いものを選ぶこともできます。
- 小さな詰まりをその場で対処できる
- 構文エラーや実行時エラーをその場で解決できるので、流れが止まりにくく、これが「早く回す」ことにつながりました。
- わからない知識もその場でAIに聞きながら進められるので、疑問の解消と理解が高速でできます。
つまずき
- 使い手の限界がAIの限界
- 生成AIは発想を「生み出す」ように見えますが、実際には自分が理解できる範囲のものしか認識できません。
- つまり、自分の知識、経験、抽象化能力が生成AIのできる限界になります。
- 例えば、自分が持っていない評価軸ではそもそもプロンプトに起こすことすらできません。
- たまたま思った以上の成果物が出力されても、その評価は自分の知識の中でしかできないので「良い/悪い」「ずれている」ことすら判断できません。
- なので、結局はAIを使いこなすためには、まず人間側が賢くなる必要があると感じました。
今回の取り組みからわかったこと
最初から丸投げするのではなく、設計からAIと伴奏することが大切
生成AIにいきなり「コードを書いて」と依頼すると、それらしい成果物は返ってきます。
しかし実際に使えるか、拡張できるか、運用に耐えるかは別問題でした。
今回は最初からコードを書かせるのではなく、設計段階からAIと対話し、レビュー役・比較役として使いました。
その結果「AIに作らせる」ではなく「AIと一緒に設計する」方が、後戻りが少なく、結果的に速いと感じました。
小さく作って早く回すことで、試行錯誤のサイクルが速くなる
犬と猫を見分けるというシンプルな題材を選んだのは、高度な精度を目指すためではなく、検証の回転数を上げるためです。
- まず動くものを作る
- すぐに壊す・直す
- その都度AIにレビューさせる
このサイクルを短く回すことで、「どのタイミングでAIを使うと効果が高いか」「人間が考えた方が早いところはどこか」が見えてきました。
生成AIを使う前提だからこそ、完璧を目指さず、小さく試すことがより重要になります。
結局、人間側が賢くなる必要がある
生成AIは、人間の知識や経験を超えて自律的に判断することはできません。
設計の良し悪しや、指摘の妥当性を最終的に判断するのは、やはり人間です。
一方で今回の取り組みを通して「人間がすべてを知っていなくても使える」ことも分かりました。
たとえば「なぜそう言えるのか」「どの前提に基づいた判断か」のようなプロンプトを与えることで、以下のようなことを明示的に説明させることができます。
- その指摘の根拠
- 前提としている設計原則
- 他に取り得る代替案
- 想定されるリスクやトレードオフ
これらを言語化させることで、人間側は結論ではなく“思考プロセス”をレビューできるようになります。
これは、人間の理解力を完全に代替するものではありませんが、知識や経験の不足を“補助輪”のように支えてくれると感じました。
ただし、この方法にも限界があります。
- 出てきた根拠が妥当かどうか
- 見落としている観点がないか
- 現実の制約(運用・組織・コスト)に合っているか
これらを判断するには、やはり人間側に一定の知識と判断力が必要です。
生成AIは「理由をそれっぽく説明する」ことは得意ですが、その理由が正しいかどうかを保証する存在ではありません。
だからこそ、プロンプトを工夫すれば “ある程度までは” 補えるが、最終的にAIの出力を活かせるかどうかは、人間側の理解力に依存するという結論に落ち着きました。
おわりに
AI分科会としての今回の取り組みは、新しい技術を「楽に使う」ためではなく、どう向き合い、どう成長につなげるかを考える実験でした。
このプロセスを他のプロジェクトにも展開し、「新しい技術を試し、理解し、業務に活かせる形に落とし込む」取り組みを続けていきます。
これからもAIを魔法にせず、道具として使いこなす取り組みを続けていきたいと思います。

