
マルチクラウドの判断基準:Why×Canで『採用/限定採用/見送り』を決める方法
こんにちは。システムマネジメントサービス2部の森内です。
オンプレ/クラウドの構築・運用・統制(ID/ログ/監査)やBCP/DR設計を担当し、「回る運用」を前提に、現場で実行できる意思決定を支援しています。
- 1. この記事の結論(先に要点だけ)
- 2. はじめに:クラウドは強い。それでもリスクはゼロにならない
- 3. 本稿の前提(用語)
- 4. この記事でわかること
- 5. 判断の全体像:Why(必要性)×Can(実行可能性)
- 6. ケースで見る:結局「採用/限定採用/見送り」はどう決まる?
- 7. マルチクラウドのメリット・デメリット(必ず払う代償)
- 8. 判断基準1:必要性(Why)――「単一クラウドでは足りない」を言語化する
- 9. 判断基準2:実行可能性(Can)――「TCOと統制」が回るか?
- 10. マルチクラウドの運用コスト:料金より人件費がTCOを支配する
- 11. マルチクラウドのガバナンス最小構成:統制MVP(90日)
- 12. ネットワーク/データ移動:転送コストと遅延は「構造問題」
- 13. 体制・スキル:最終責任者と「属人化しない設計」が先
- 14. 採用判断チェック(Yes/No)――この結果が「3択」に直結する
- 15. 限定採用のおすすめパターン(現実解)
- 16. よくある質問(FAQ)
- 17. まとめ:結局、マルチクラウドは合理的か?
- 18. 次のステップ(社内で「決め切る」ために)
- 19. 参考(一次情報・フレームワーク)
- 20. 免責事項
この記事の結論(先に要点だけ)
- マルチクラウドは「止まらない仕組み」ではなく、止まり方を設計するための保険です(保険料=運用・統制コスト)。
- 判断は Why(必要性)×Can(実行可能性) で十分です。結論は「採用/限定採用/見送り」の3択に落とします。
- 採用(または限定採用)するなら、最初にやるべきは構成ではなく統制MVP(目安90日:入口→証跡→逸脱)です。
はじめに:クラウドは強い。それでもリスクはゼロにならない
主要クラウド(AWS/Azure/Google Cloud(GCP)など)は高い冗長性と運用実績を前提に設計されています。
ただし、広域障害や基盤起因の不具合、大規模変更の連鎖(人為ミスを含む)によって、復旧が長引く可能性は残ります。
言い換えると、クラウドは強い一方で、どれだけ備えてもリスクを「ゼロ」にはできません。
ここで押さえたいのは、「クラウドを増やせば止まらない」わけではないという点です。
マルチクラウドであっても、IdP/SSO、DNS、CDN、監視SaaS、社内ネットワーク、運用承認フローなどの共有依存が単一障害点(SPOF)になれば、サービス全体は止まり得ます。
したがって可用性は、単純に「上げる」ではなく、どのリスクに対して、どの止まり方を許容するかを設計する発想が重要です。
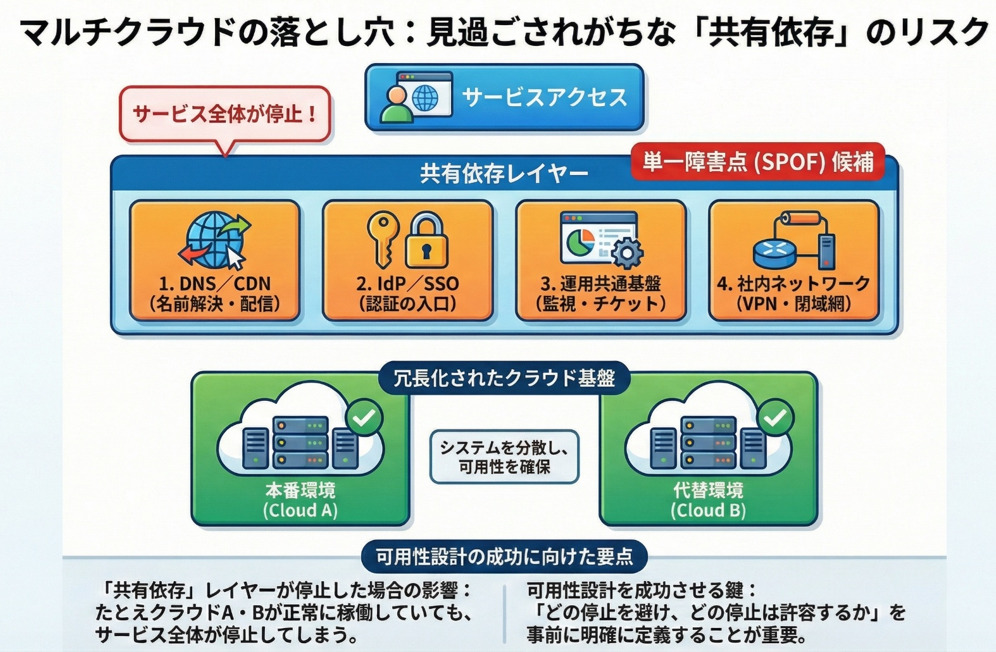
もし「事業者起因で本番が止まった」とき――自社のサービスは、事業として耐えられるか?
本稿の前提(用語)
本稿でいう「マルチクラウド」は、複数のパブリッククラウド(例:AWS/Azure/Google Cloud(GCP))をまたいで、ひとつの業務システム/機能/サービスを「同じ運用・統制の枠組み」で扱う状態を指します。
(例:本番二重化[Active-Active/Active-Passive]、DRのみ別クラウド、分析基盤のみ別クラウドなど)
- 「部門ごとに別クラウドを結果的に使っている(請求・ID・ログが別々)」状態と、「複数クラウドを併用してひとつの業務システム/機能/サービスを運用する」状態では、運用負担の増え方がまったく異なります。本稿の主対象は後者です。
- オンプレ併用の「ハイブリッドクラウド(オンプレ+クラウド)」は主題から外れるため、違いはFAQで補足します。
本稿での呼び分け
- 限定採用:DRのみ/分析のみ等、目的(Why)が立つ範囲に絞って複数クラウドを併用する
想定読者:情報システム部門/開発部門の責任者、SRE/基盤チーム、クラウド移行の稟議・設計・運用に関わる方
本稿で使う略語は次の通りです。
- TCO:Total Cost of Ownership(総保有コスト)
- BCP:Business Continuity Plan(事業継続計画)
- DR:Disaster Recovery(災害・大規模障害からの復旧)
- AZ:Availability Zone(可用性ゾーン)
- SPOF:Single Point of Failure(単一障害点)
- Best-of-Breed:用途ごとに「最も強い」クラウドサービスを選び、適材適所で組み合わせる考え方(機能最適)
- FTE:Full-Time Equivalent(フルタイム換算の要員数)
- IdP/SSO:Identity Provider/Single Sign-On(認証基盤/シングルサインオン)
- IAM:Identity and Access Management(認証・認可の管理)
- IaC:Infrastructure as Code(構成のコード管理)
- SLO:Service Level Objective(目標とするサービス品質)
- SLA:Service Level Agreement(サービスレベル合意)
- SIEM/CSPM:セキュリティ監視/クラウド設定評価の仕組み
- MSP:Managed Service Provider(運用委託先)
- RTO:Recovery Time Objective(目標復旧時間)
- RPO:Recovery Point Objective(目標復旧時点/許容データ損失)
- MVP:Minimum Viable Product(実用最小限のプロダクト)。最小で回し、学びを反映して段階改善する考え方(本稿では「統制MVP」)
- DoD:Definition of Done(完了の定義。ここでは「運用できる状態」の最低条件)
- FinOps:クラウド費用を継続的に可視化・配賦・最適化する運用(体制とプロセスを含む)
- Exit Plan:脱出計画(データ/構成/運用を、別環境へ移す手順とテストの計画)
この記事でわかること
- マルチクラウドを「採用/限定採用/見送り」で決めるための判断軸(Why×Can)
- 利用料ではなく、人件費込みTCO(運用・統制コスト)で比較する見積もり観点とテンプレ
- 採用する場合に避けて通れない、統制MVP(90日)の最小セット(入口→証跡→逸脱)
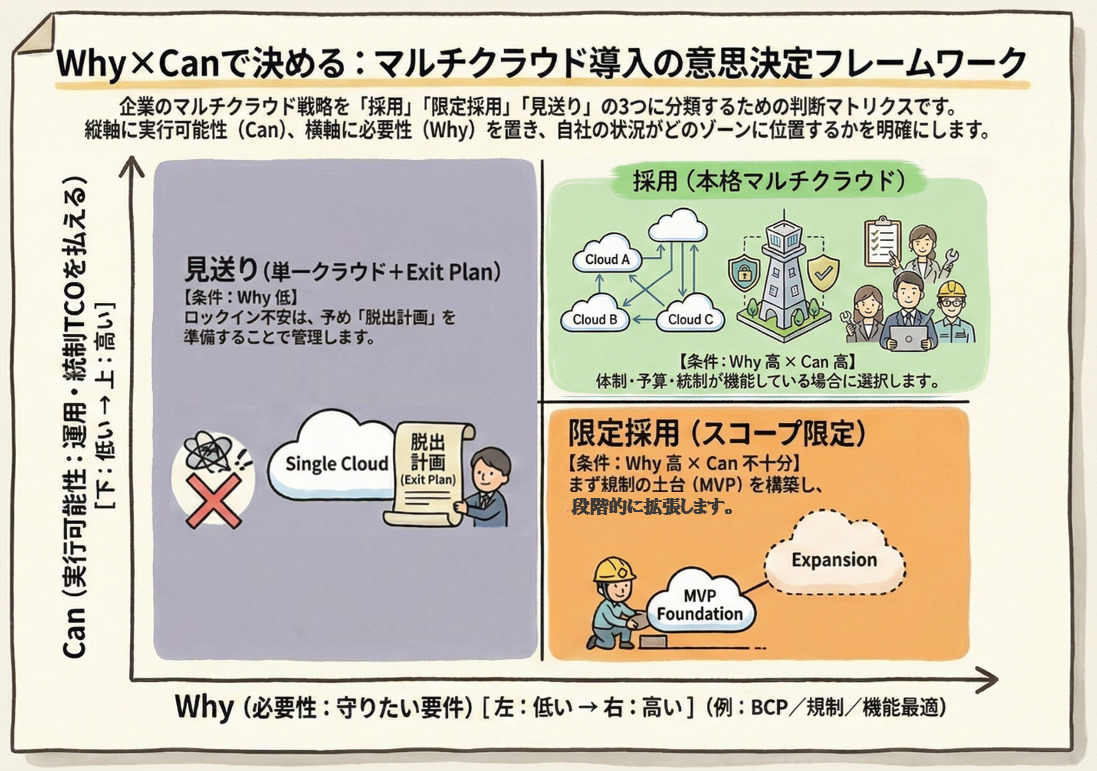
判断の全体像:Why(必要性)×Can(実行可能性)
マルチクラウドは「やる/やらない」ではなく、どの範囲に「保険料(運用・統制コスト)」を払うかの設計です。
ここで大事なのは、技術の優劣ではなくWhy(守りたい要件)とCan(払い続けられる運用TCOと体制)を同じ土俵に置くことです。
まずは次の2軸で、現状の立ち位置を確認します。
- Why(必要性)が強い状態
- 事業者起因の長時間停止が事業的に許容できない
- 規制・データ主権・地政学などで1社依存が実質不可
- 機能最適(Best-of-Breed)で定量効果が見込める
- Can(実行可能性)が高い状態
- 追加TCO(要員・監査・ツール・教育・ネットワーク)を予算化できる
- 統制MVPを回す責任者と会議体がある
- 中核メンバーを複数確保し、属人化しない運用ができる
- 判断結果の目安(3択)
- 採用(本格マルチクラウド):Whyが強く、Canも高い(体制・予算・統制が継続できる)
- 限定採用(スコープ限定):Whyはあるが、Canは整備途上(まずはDRのみ/分析のみ等、目的が立つ範囲に絞る)
- 見送り(単一クラウド+Exit Plan):Whyが弱い、またはCanが重い(多重化の前に「回る運用」と脱出計画でリスクを管理可能にする)
ケースで見る:結局「採用/限定採用/見送り」はどう決まる?
同じ「マルチクラウド検討」でも、結論が割れる理由はシンプルです。
Why(守りたい要件)とCan(払い続けられる運用TCO)の組み合わせが違うからです。
ケース1:規制で「1社依存不可」――採用(本格マルチクラウド)
- Why:監査要件としてマルチベンダーが必須。停止よりも「依存の形」がリスク。
- Can:統制(IdP/ログ/例外)と24時間365日(24/7)体制が既にある。追加TCOを予算化できる。
→ 結論:本格マルチクラウドが合理的。最初から統制MVPを「強め」で設計する。
ケース2:BCPは強いが、体制が薄い――限定採用(DRのみなど)
- Why:広域停止の影響は大きい。ただしRTO/RPOは「数時間」で許容できる。
- Can:中核が1〜2名。監査ログも分散。いきなり二重化すると、運用破綻が見える。
→ 結論:まずはDRのみ別クラウドなどで限定採用。統制MVP(90日)で土台を作ってから段階拡張。
ケース3:動機が「何となくロックイン不安」――見送り(単一クラウド+Exit Plan)
- Why:明確な規制・BCP要件はなく、機能最適も定量効果がまだ弱い。
- Can:転送量も把握できておらず、追加要員の目途も立たない。
→ 結論:マルチ化は時期尚早。Exit Plan(持ち出し手順の整備とテスト)+共通レイヤー(ID/ログ/CI/CD)で不安を「管理可能」にする。
マルチクラウドのメリット・デメリット(必ず払う代償)
得たいもの(メリット)
- BCP/DR強化:広域障害・災害まで含めて継続性を高める
- 交渉力・依存低減:価格・契約・供給停止リスクへの備え
- 機能最適(Best-of-Breed):強いサービスを適材適所で使う
増えやすいもの(代償:多くのケースで発生)
- 運用負担(人件費):監視・障害対応・変更管理・教育が増える
- 統制の複雑化:IAM/ログ/設定管理が複線化し、監査が重くなる
- データ移動コスト/遅延:エグレス課金とレイテンシが増えやすい
ポイント:メリットだけで判断すると、期待した効果が出にくく、運用負担が先行しやすくなります。
マルチクラウドは「得」と「代償」をセットで抱える構造です。
判断基準1:必要性(Why)――「単一クラウドでは足りない」を言語化する
目的の棚卸しです。ここが曖昧なまま進めると、効果が出る前に運用・統制コストだけが先行し、投資対効果の説明が難しくなります。
マルチクラウドの目的は主に3つです。
- BCP/DR(事業継続/災害復旧)
- 交渉力(ロックイン回避)
- 機能最適(Best-of-Breed)
BCP効果の実態:単一クラウドで足りる範囲/足りない範囲
BCPはRTO(復旧時間)/RPO(許容データ損失)を、まず事業の損失から逆算して決めると議論が速くなります。
例:停止1時間あたりの損失(売上機会損失+SLA返金/違約金+復旧要員の追加費+機会損失)を概算し、許容できる停止時間をRTOとして固定します。
RPOも同様に、失ってよいデータ(取引・監査証跡・ログなど)の許容範囲を整理して定義します。
RTO/RPOが現実的な範囲に収まり、かつ復旧訓練(手順・権限・バックアップ検証)を継続運用できるのであれば、単一クラウドのマルチリージョン(または複数AZ)+バックアップ+訓練で要件を満たせるケースは多いです。
一方で、設計があっても訓練が回らない場合、単一/複数に関わらずBCPが形骸化しやすくなります。成否は構成よりも運用の継続性に寄りがちです。
- 想定停止
- 単一クラウドで満たしやすい:リージョン/AZ障害中心
- マルチクラウドを検討しやすい:事業者レベルの広域停止も許容できない
- 目標RTO/RPO
- 単一クラウドで満たしやすい:数十分〜数時間/RPOも現実的
- マルチクラウドを検討しやすい:極端に短いRTO/RPO、かつ単一依存がリスクになる
- 監査・規制
- 単一クラウドで満たしやすい:監査証跡を単一基盤で整えられる
- マルチクラウドを検討しやすい:「1社依存が不可」と明確に要求される
- 運用条件
- 単一クラウドで満たしやすい:訓練・権限・バックアップ検証を継続できる
- マルチクラウドを検討しやすい:複数クラウドでも訓練・統制を回せる体制がある
なお、マルチクラウドにしても人為ミス(設定ミス、権限誤り、手順漏れ)は消えません。
むしろクラウドが増えるほど、ミスが起きうる「面積」は広がります。
だからこそ、後述する統制(入口→証跡→逸脱)が前提になります。
加えて、マルチクラウドでも共有依存は残ります。
たとえば、IdP/SSO、DNS、CDN、決済、監視SaaS、社内ネットワーク、運用承認フローが単一のままだと、クラウドを分けても「止まるところは止まる」状態になり得ます。
マルチクラウドで守れるのは主に「クラウド事業者側の特定レイヤーの停止」であり、依存関係を棚卸しして、どこが単一障害点(SPOF)かを明示することが前提です。
また、本番二重化(特にActive-Active)は、データ整合性・分断耐性・切り替え手順の難易度が一気に上がります。
「できるか」ではなく、「どの整合性を捨て、何を守るか」を最初に決めないと、設計も運用訓練も成立しません。
ロックイン対策は「マルチ化」以外でもできる(Exit Plan)
「ロックインが怖い」は、たいてい次の3つに分解できます。
- データ移行の困難さ(データ量・形式・転送費)
- クラウド固有サービスへの依存(代替が効かない)
- 人材・ノウハウの依存(特定クラウドしか触れない)
単一クラウドでも、以下で不安はかなり下がります。
- データ持ち出し手順を明文化し、定期的にテストする
- 共通レイヤー(IdP/SSO、ログ、CI/CDなど)を先に統一しておく
- 依存してよい領域/避ける領域を最初に線引きする(差別化は固有でもOK、止められない基幹は移植性重視など)
機能最適(Best-of-Breed)は「境界線」が命
機能最適は魅力的ですが、境界が曖昧だと運用が二重化します。
- 共通化すべき横串:IdP/SSO、ログ・監視、タグ命名、ポリシー
- 固有でよい領域:採用理由になるサービス(分析、AI、特定DBなど)
「どこまで共通、どこから固有か」を先に決めるだけで、運用難易度とコストの膨らみ方が大きく変わります。
判断基準2:実行可能性(Can)――「TCOと統制」が回るか?
目的(Why)があっても、回らない体制で始めると対応コストが跳ね上がりやすくなります。
判断基準2(Can)で見るのは、次の3点だけです。
- TCO(人件費込み):追加FTE/オンコール/監査・統制工数/ツール/教育/ネットワーク
- 統制(入口→証跡→逸脱):IdP/SSO、監査ログ集約、ベースラインと例外運用
- 体制(責任の設計):オーナー、RACI、24/7、一次対応、FinOps
この3つに「回る見通し」が立つなら前に進めます。
見通しが弱いなら、まずはスコープを絞った限定採用が安全です。
マルチクラウドの運用コスト:料金より人件費がTCOを支配する
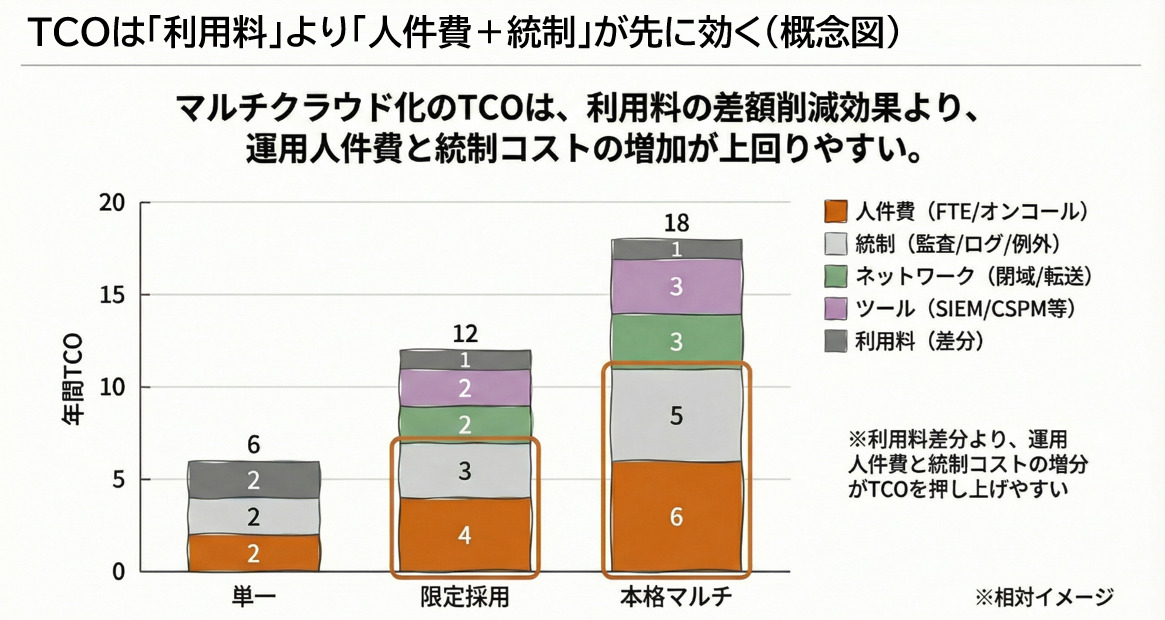
「クラウド利用料が安いから得」は誤解を生みやすいので注意が必要です。
マルチクラウドは追加人月が増えるほどTCOが膨らむからです。
見積もりに入れるべきTCO(代表例)
- 追加要員(FTE):運用・監視・変更管理が増える
- オンコール:待機/深夜対応/手当・割増
- 監査・統制対応:証跡収集、権限棚卸し、ログ保全
- IaC運用:テンプレ整備・保守(クラウドごとの調整が増える)
- ツール費:監視、ログ、SIEM、CSPM、CI/CD、Secrets管理
- 教育・採用費:複数クラウドの学習と人材確保
- ネットワーク費:クラウド間接続、転送(エグレス)
稟議でブレないコツ:比較の単位を「年間TCO」に固定します。
年間TCO(概算)=追加FTE+オンコール+監査・統制工数+IaC保守+ツール費+教育・採用費+ネットワーク(回線+転送料)
一般に、要件や体制が増えるほど運用・統制の増分がTCOに与える影響が大きくなりやすいため、まずこの箱で比較すると意思決定が速くなります(規模・要件により変動します)。
例(概算・仮定):追加FTEが2名で、1人あたり年間コスト(人件費+間接費+採用/教育の按分)を仮に1,500万円と置くと、追加人件費だけで3,000万円/年です。
外注運用に置き換える場合も、「月額運用費(1人月単価×稼働人月)×12」で同じ箱に入れると比較がブレません。
※単価は企業規模・地域・内製/外注比率で変わるため、必ず自社の原価(または委託単価)に置き換えて試算してください。
まず作るべき「TCO試算の箱」(テンプレ)
「議論が平行線」の原因は、だいたい比較の箱が揃っていないことです。
最初に、下の箱だけでも作ると稟議が進みます(数字は概算でOK)。
TCO試算テンプレ(年間)
※「単一/限定/本格」を同じ箱で比較するための記入表です(数値は概算でOK)。
| No | 項目 | 単一クラウド | 限定採用 | 本格マルチクラウド | メモ(増分の理由) |
|---|---|---|---|---|---|
| 1 | 追加FTE(人) | 監視/変更/運用/基盤の増分 | |||
| 2 | オンコール(回数/時間) | 待機+呼出+深夜係数 | |||
| 3 | 監査・統制(工数) | 棚卸し/証跡/例外対応 | |||
| 4 | BCP/DR訓練(回数/工数) | 切替演習、手順検証、監査対応 | |||
| 5 | IaC整備・保守(工数) | テンプレ差分が増える | |||
| 6 | セキュリティ運用(工数/年額) | 設定評価、キー運用、診断など | |||
| 7 | 教育・採用(年額) | 研修/資格/採用コスト | |||
| 8 | ツール費(年額) | 監視/ログ/SIEM/CSPM等 | |||
| 9 | サポート契約(年額) | サポートプラン増分 | |||
| 10 | 契約・法務・ベンダーマネジメント(工数) | 契約更新、監査、窓口対応 | |||
| 11 | クラウド間接続(回線/装置) | 閉域/専用線/機器費・運用 | |||
| 12 | ネットワーク転送(GB/月) | エグレス課金(見積は月次) | |||
| 13 | 合計(年額) | 「利用料」はこの一部 |
マルチクラウドのガバナンス最小構成:統制MVP(90日)
「統制は後で」から始めると、監査や事故対応のたびに「証跡が揃わない/権限が追えない」が表面化します。
結果としてスピードも落ちます。
最初から完璧な統制は非現実的でも、順序(入口→証跡→逸脱)を守れば、最小構成で「回し始める」ことは現実的です。
統制MVP(目安:90日)— 実行順と成果物
| 期間 | 目的 | 主要タスク | 成果物(例) | DoD(完了の目安) |
|---|---|---|---|---|
| Day 0〜30 | 入口を一本化(誰が入ったか) | IdP/SSO統一、管理者権限ルール、ブレークグラス、権限申請フロー | IdP接続方針、管理者権限ルール、ブレークグラス手順、申請フロー(暫定版) | 管理者が原則SSO経由で入れる/ブレークグラスの保管/利用/記録が定義され月1回で確認できる |
| Day 31〜60 | 証跡を揃える(何が起きたか) | 監査ログ集約、重要イベント検知、一次受け→エスカレーション線引き | ログ集約先と保管要件、検知ルール一覧、一次受け・エスカレーション手順 | 保管期間と検索手順が定義され実際に引ける/重大イベントの通知先と当番が決まる |
| Day 61〜90 | 逸脱を止める(やってはいけないを仕組みに) | ベースライン定義、逸脱検知、例外申請→期限管理→棚卸し定例 | ベースライン文書/テンプレ、例外フロー、棚卸し会議体と責任者 | 逸脱→例外申請→期限で棚卸しの流れが回る/月次または四半期の棚卸しが開始している |
統制は「禁止」ではなく「管理」です。例外を設計しない統制は、現場で必ず破れ、監査で揉めやすくなります。
統制MVPの前提(最低限これだけは必要)
- オーナー(最終責任者)がいる
- 既存のIdPやログ基盤を活用できる(または用意する意思がある)
- 合意形成を止めない(決める場がある)
Day 0〜30:入口を一本化(認証・権限の「誰が」を固める)
- IdP/SSOの統一(入口が揃わないと統制が始まらない)
- 管理者権限ルール(ブレークグラス用アカウントを含む)
- 権限申請・承認フロー(暫定でよいが「通る道」を作る)
成果物(例):IdP接続方針、管理者権限ルール、ブレークグラス手順、権限申請フロー(叩き台)
DoD(完了の目安):
- 管理者が原則SSO経由で入れる
- ブレークグラスの保管/利用/記録が定義され、月1回は手順が確認できる
Day 31〜60:証跡を揃える(監査・事故調査の「何が起きたか」を残す)
- 管理者操作ログ(監査ログ)を1カ所に集約
- 重要イベント(権限変更/鍵操作/公開設定変更)の検知・アラート
- 一次受け→エスカレーションの運用線引き(24/7を前提にするか、委託するかを決める)
成果物(例):ログ集約先(ログ基盤/SIEM)と保管要件、重要イベント検知ルール一覧、一次受け・エスカレーション手順
DoD(完了の目安):
- 監査ログの保管期間と検索手順が定義され、実際に引ける
- 重大イベントの通知先と当番/担当が決まっている
Day 61〜90:逸脱を止める(「やってはいけない」を仕組みにする)
- 設定ベースライン(暗号化、公開範囲、タグ、鍵管理)を定義
- 逸脱検知→例外申請フロー→期限管理→棚卸しの定例化
- 例外を「禁止」ではなく「管理」に落とす(監査で揉めない)
成果物(例):ベースライン(ガードレール)文書/テンプレ、逸脱検知の運用設定、例外申請〜期限管理フロー、定例棚卸しの会議体と責任者
DoD(完了の目安):
- 逸脱が検知され、例外申請に流れ、期限で棚卸しされる
- 月次(または四半期)の棚卸し会議が回り始めている
ネットワーク/データ移動:転送コストと遅延は「構造問題」
クラウド間でデータが動くほど、エグレス課金が積み上がります。
加えて、経路が増えるほど遅延のばらつきと障害時の切り分け難が増えます。
避けたいアンチパターン(よくある落とし穴)
- DBはクラウドA、分析はB、ログはC……のように、日常的に往復通信している
→ コスト増・遅延増に加え、障害時の切り分け(原因特定)が難しくなりやすいため注意が必要です。
回避の原則(覚えやすい3つ)
- 同居:強く依存するもの同士(アプリと主要DB)は同一クラウドへ
- 非同期:またぐならキュー/イベントで非同期化し、通信回数を減らす
- 閉域(必要時):Direct Connect/ExpressRouteなどは有効だが、運用負担も増える
体制・スキル:最終責任者と「属人化しない設計」が先
マルチクラウドは、技術よりも運用責任の設計で詰まります。
- まず決める:最終責任者(Platformオーナー/SRE責任者)と24/7 一次対応方針(内製かMSP委託か)
- 次に固める:RACI(R=実行、A=最終責任、C=相談、I=報告)で揉めない分担へ
- 現実ライン:中核メンバーは最低でも2〜3名(運用・改善・監査対応を分担できる体制)。1人運用は属人化し、むしろリスクが増えます。
最初から「全社マルチ」ではなく、限定採用でテンプレと運用を育てるのが安全です。
採用判断チェック(Yes/No)――この結果が「3択」に直結する
判断基準1:必要性(Q1〜Q4)
- Q1. RTO/RPOが単一クラウドのマルチリージョンでは満たせない
- Q2. 事業者起因の広域障害が事業的に許容できない
- Q3. 機能最適(分析/AIなど)で定量効果が見込める
- Q4. 規制・データ主権・地政学で1社依存が実質不可
判断基準2:実行可能性(Q5〜Q15)
- Q5. クラウド間通信の棚卸しと月次転送量の概算がある
- Q6. 追加TCO(要員・オンコール・監査・IaC・ツール・教育)を見積もり、予算化の目途がある
- Q7. 【Must】IdP/SSO中心のIAM統合方針がある
- Q8. 【Must】管理者操作ログ(監査ログ)の集約と保管要件が決まっている
- Q9. 設定ベースラインと例外処理フローが設計できる
- Q10. 監視・障害対応のSLO、一次対応体制が決まっている
- Q11. IaC標準化と保守責任者が決まっている
- Q12. 【Must】横断的に意思決定できる責任者/会議体がある
- Q13. 【Must】中核メンバーを複数確保でき、属人化しない見通しがある
- Q14. FinOps(配賦・予算アラート・最適化)を運用できる
- Q15. 最初に試す限定採用の範囲が合意されている
判定ルール(迷わないための目安)
Yes数は「目安」として便利ですが、重みがあります。
特に判断基準2のMust(Q7/Q8/Q12/Q13)が未充足のまま本番二重化へ進むと、監査・障害対応・権限統制のいずれかで詰まり、運用が先に破綻しやすくなります。
そこで本稿では、迷いにくいように判定の順序を固定します。
- Mustが埋まっているか(未充足なら原則「限定採用」以下)
- 判断基準1(Why)が2つ以上あるか(0〜1なら「見送り」寄り)
- 判断基準2(Can)が90日で統制MVPを回し始められる見通しか(弱いなら「限定採用」)
判定の目安は次の通りです。
- 見送り(単一クラウド+Exit Plan):判断基準1のYesが0〜1、またはMust未充足で体制・統制が立たない
- 限定採用(スコープ限定):判断基準1が2以上あるが、判断基準2は整備途上(まず統制MVPで土台作り)
- 採用(本格マルチクラウド):判断基準1が3以上あり、Mustも満たし、運用と統制を継続できる体制・予算がある
境界ケースは、まず限定採用で弱点(ログ統合・監査・体制)を補強してから段階拡張するのが堅実です。
限定採用のおすすめパターン(現実解)
- DRだけ別クラウド型(BCP特化):バックアップ先/待機系のみ他クラウド
- 分析/AIだけ別クラウド型(機能特化):得意領域だけスポット採用
- 特定リージョンだけ別クラウド型(規制対応):地域要件を満たすための限定利用
※いずれも前提は、共通レイヤー(ID・ログ・タグなど)を先に揃えることです。
よくある質問(FAQ)
Q1. マルチクラウドとハイブリッドクラウドの違いは?
A. マルチクラウドは複数のパブリッククラウドを併用します。
ハイブリッドはオンプレ/自社DC+クラウドの組み合わせです。
Q2. BCP目的なら単一クラウドのマルチリージョンで十分?
A. 多くは十分です。
マルチクラウドが必要なのは、「事業者の長時間停止も許容できない」または「規制などで1社依存が不可」のケースが中心です。
Q3. マルチクラウド運用は最小で何人必要?
A. 目安として中核2〜3名+(必要に応じてMSP)です。
1人運用は属人化し、保険になりません。
Q4. ロックイン不安はマルチ化しないと解消できない?
A. いいえ。
Exit Plan(データ持ち出し手順の整備とテスト)と、ID/ログなど共通レイヤーの統一で大きく低減できます。
Q5. 監査・統制は何から手を付けるべき?
A. 最優先はIdP/SSOで入口を一本化することです。
次に監査ログ集約、最後に設定ベースラインと例外フロー(統制MVP:90日)を整えます。
まとめ:結局、マルチクラウドは合理的か?
マルチクラウドは、可用性のための万能薬ではなく「保険料(運用・統制コスト)を払う設計」です。
合理性は、技術の優劣ではなくWhy(守りたい要件)× Can(払い続けられる体制とTCO)で決まります。
- 採用(本格マルチクラウド)が合理的になりやすい条件:Whyが強い(規制・BCP・定量効果のある機能最適)うえで、統制MVP(入口→証跡→逸脱)と運用体制(RACI/一次対応/FinOps)を継続運用できる
- 見送り(単一クラウド+Exit Plan)が合理的になりやすい条件:動機が「ロックイン不安」中心で、追加TCOを捻出できない/転送量・依存関係の把握が不十分(まずはExit Planと共通レイヤー整備でリスクを「管理可能」にする)
- 現実解として成功しやすい(限定採用):スコープを絞って開始し、共通レイヤー(ID・ログ・タグ)→統制MVP→段階拡張で成功確度を上げる
次のステップ(社内で「決め切る」ために)
- まずは判断基準1/判断基準2チェックで、採用/限定採用/見送りの現在地を可視化する
- 限定採用なら、統制MVP(90日)を先に計画し、最初のスコープ(対象/データ/環境)を合意する
- 見送りなら、Exit Plan(脱出計画)と共通レイヤー整備でロックイン不安を「管理可能なリスク」に落とす
「やりたい運用が回るか不安」という段階でも問題ありません。
不安のまま突っ込むのではなく、チェックと段階設計で「勝てる形」に整えてから進めましょう。
参考(一次情報・フレームワーク)
※本稿は一般的な検討観点の整理です。詳細設計・統制要件は、各クラウド/フレームワークの一次情報も参照してください。
- AWS Well-Architected Framework
https://docs.aws.amazon.com/wellarchitected/latest/framework/welcome.html - Microsoft Azure Well-Architected Framework
https://learn.microsoft.com/azure/well-architected/ - Google Cloud Architecture Framework
https://cloud.google.com/architecture/framework - FinOps Framework(クラウド費用の継続最適化)
https://www.finops.org/framework/ - (参考)クラウドの責任共有モデル
各社のセキュリティ/コンプライアンス文書にて定義
免責事項
本稿は一般的な検討観点の整理であり、特定の環境・業種・規制要件に対する個別の設計判断を保証するものではありません。
実際の採用可否は、システム特性(RTO/RPO、データ特性、依存関係、監査要件)と体制・予算を踏まえて検討してください。

