

AIOps×生成AIで運用を自動化! ― SREの仕事はなくなるのか、進化するのか?
序章 「Alert Storm」を終わらせる物語
こんにちは。プラットフォーム技術部の森内です。
深夜、監視モニターにアラートが次々と吹き荒れる。まさに「Alert Storm」状態です。平均復旧時間(MTTR)が1時間を超える企業も少なくありませんが、Enterprise Management Associates(EMA)による2024年調査では、AIOpsを成熟導入した組織の50%以上がMTTRを1時間未満に短縮し、そのうち19%は30分未満で復旧できたと報告されています(O’Connell, 2024)。
オンコールのエンジニアたちが毎晩のように疲弊する状況でも、AIOps+生成AIの導入によりアラートの相関分析と自動修復を組み合わせれば、復旧プロセスを短縮できる可能性があります。人手による対応時間を圧縮できれば、エンジニアの負担軽減だけでなく顧客への影響も最小化できます。
こうした事例は他人事ではありません。人材不足とシステムの複雑化という二重苦が、今や多くのIT運用現場を悩ませています。Veeamの国際調査では、DXの阻害要因として「レガシー技術」が40%、「ITスキル不足」が44%挙げられています(Veeam Software, 2020)。容赦なく降り注ぐアラートの嵐に、人手だけで立ち向かうのは限界に近いのです。
では、人間とAIの役割分担でこの状況を打開できるでしょうか。比喩的に言えば、SRE(Site Reliability Engineering)を担うエンジニアは外科医、AIはオートパイロットのような関係です。熟練の外科医が繊細な手術に専念し、定型的な処置は手術支援ロボットに任せるように、定常作業はAIに任せ、人間は高度な判断と創造的解決に集中できます。
本記事では、AIOps(AIを活用したIT運用)と生成AIを組み合わせた自律運用の全貌と、その導入戦略を具体的に解説します。読者ご自身の組織でもすぐに実践に移せるヒントが満載です。それでは、アラートの嵐を終わらせる物語を紐解いていきましょう。
※本文中ではSREを、本来の”Site Reliability Engineering”という概念だけではなく、それを担い実践する”Site Reliability Engineer”という職務や人の意味でも用いていますことをご了承ください。
第1章 AIOps×生成AIの核心を掴む
定義と進化:第1世代AIOpsから第2世代へ
まずAIOps(AI for IT Operations)の基本を押さえましょう。AIOpsとは、IT監視やインシデント対応のツールチェーンにAI/機械学習を組み込み、自動化と高度化を図る概念です。
2016年にガートナーが提唱し始めた当初のAIOpsプラットフォームは、主に統計解析や機械学習でメトリクスを分析し、アラートのノイズを低減したり傾向を可視化したりすることに焦点が当たっていました(Gartner, 2016)。しかし根本原因の究明や対応策の実行には依然として人間の判断が必要で、「検知まではAI、復旧対応は人間」という境界が存在したのです。
近年登場した第2世代AIOpsは、生成AIを統合することで様変わりしつつあります。大規模言語モデル(LLM)の文脈理解力と文章・コード生成力を組み合わせることで、AIOpsは単なる「アラートの発信者」から「自律的な問題解決者」へと進化しています。
従来は応答なしのアラートメールで終わっていたケースでも、生成AI統合型ではチャットボットが運用エンジニアと対話しながら原因分析や対応案の提示まで行うことが可能です。これはリアクティブ(事後対応)からプロアクティブ(事前対応)、さらにオートノマス(自律対応)への根本的シフトを意味します。
こうした第2世代AIOpsは「エージェント指向(Agentic)AIOps」とも呼ばれ、AIが人間の代わりに実行まで担う点が特徴です(Poda, M, 2025)。例えるなら従来型AIOpsが「煙を検知して警報を鳴らす」煙感知器だとすれば、エージェント型AIOpsは「自動で消火まで行う」スプリンクラーのような違いがあります。AIが提案を出し、人が判断して実行する従来モデルから、AIが判断し自動実行し、人間は監督するという役割の逆転が起こりつつあるのです。
AIOpsプラットフォームの5レイヤー機能モデル
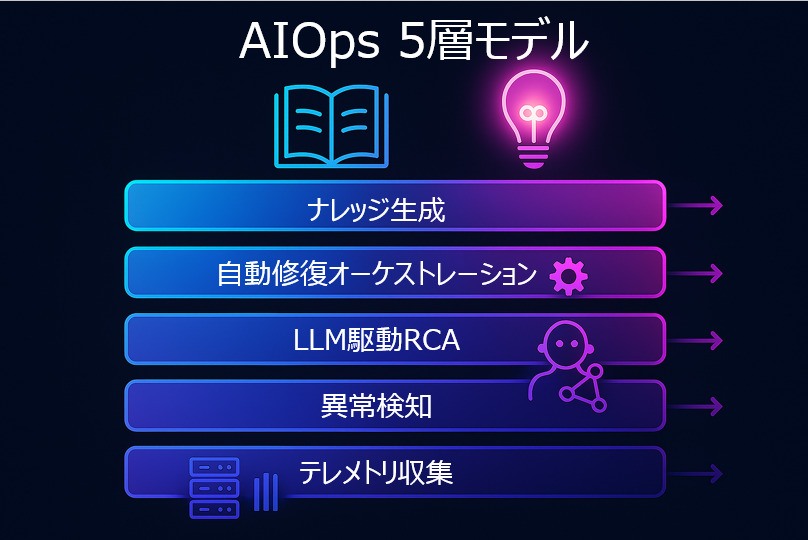
AIOps×生成AIの仕組みを体系的に理解するため、典型的な5つの機能レイヤーに分けて説明します。各レイヤーは下層から上層へと連携し、データを取り込み、分析し、行動し、最後に知見を蓄積するパイプラインを構成します。
- テレメトリ収集・整形(Observability 強化)
まずは運用データを統合的に収集します。メトリクス、ログ、トレース、イベント、場合によってはユーザーからのフィードバックまで対象は多岐にわたります。データレイクに蓄積する前にフォーマット変換やタグ付けをおこない、相互参照しやすい形へ整形することが重要です。可観測性が不十分ではAIも十分に機能しません。
- 異常検知 & ノイズ削減(Analytics 自動分析)
収集した大量データを基に、統計モデルや機械学習モデルがベースラインからの逸脱をリアルタイムに検出します。関連アラートの相関分析によりノイズを除去し、真に重要なインシデントだけを抽出します。
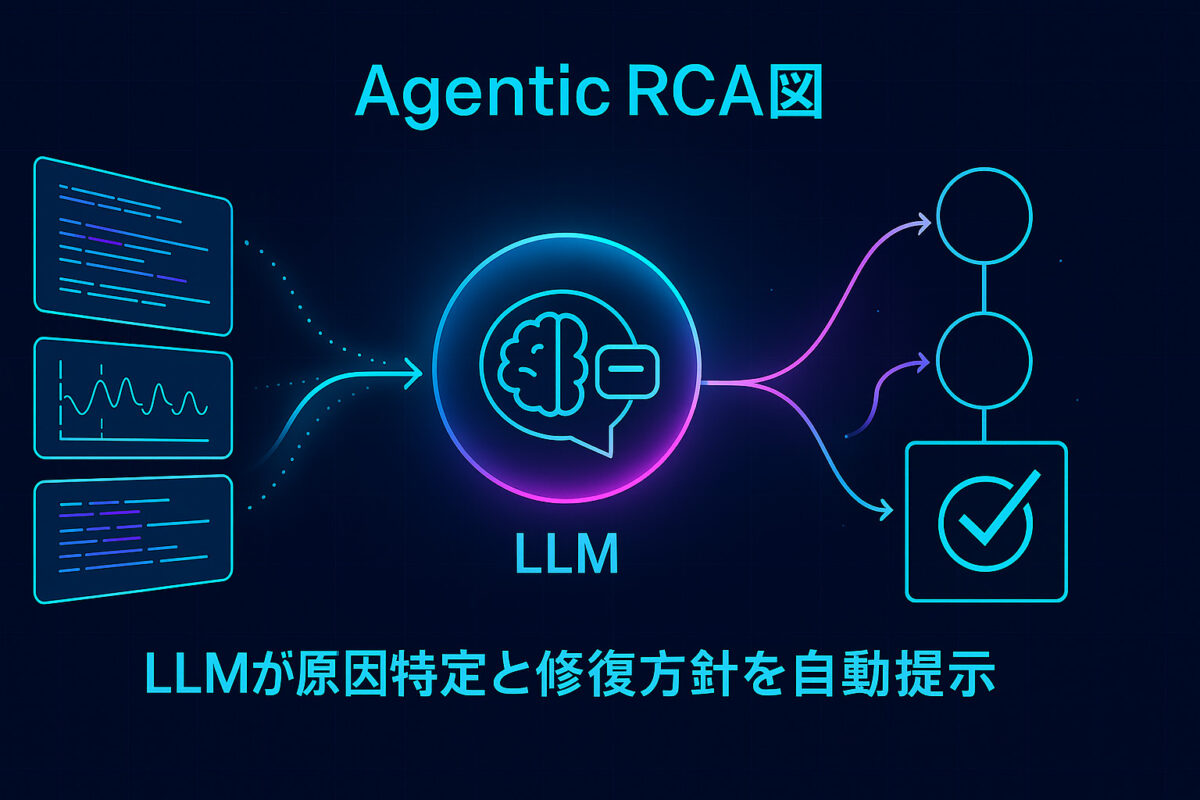
- LLM駆動の根本原因分析(RCA)
大量のメトリクスやログ、過去事例をLLMが横断的に解析し、人間のような推論で原因を突き止めます。LLMエージェントが因果関係グラフを生成し、最も疑わしい原因と推奨対処を自然言語でレポートします。従来は数時間かかった作業が数分で完了するため、MTTR(平均復旧時間)が大幅に短縮されると予測されています。
- 自動修復オーケストレーション
特定された原因に対する対処アクションを自動実行します。たとえばメモリリークが原因なら該当サービスのコンテナを再起動、リリース直後の不具合なら前バージョンへロールバックといった処置を自動化できます。本番環境ではポリシーに基づくガードレール(Policy‑as‑Code)を設定し、自動化の範囲と人間の承認範囲を明確化することが不可欠です。
- ナレッジ生成(知識蓄積と共有)
インシデントの発生から解決までの流れをAIが振返りレポートとして自動生成し、社内に展開します。生成されたレポートはナレッジベースに蓄積され、将来のRCAに再利用されることで、フライホイール型の継続的改善ループを形成します。
AIOps データフライホイールで進化する運用
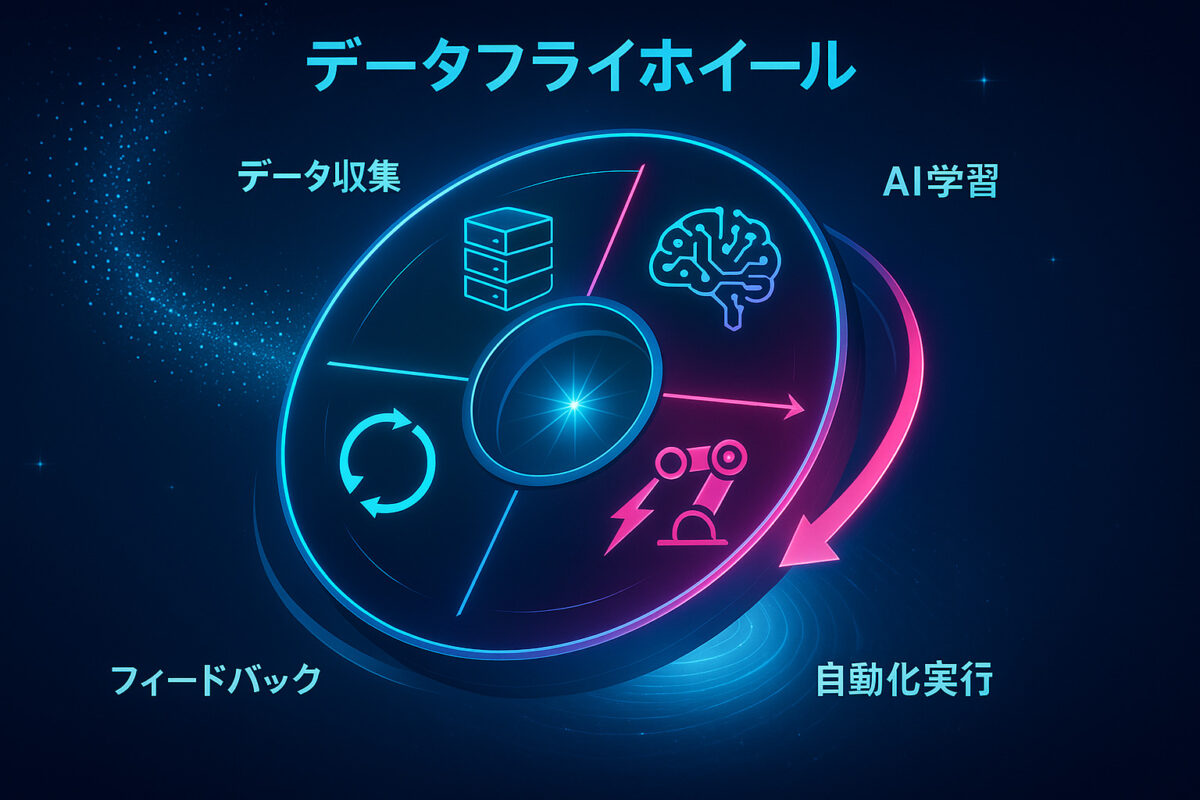
AIOps×生成AIの価値は、一度きりの自動化に留まらず、使うほどに精度と効果が増す自己成長性にあります。これを端的に表すのが「AIOps データフライホイール」という考え方です。好循環は以下のように回り続けます。
- データ活用の循環
運用で得られる膨大なデータ(メトリクス・ログ・インシデント記録など)をAIが学習素材として取り込みます。 - 学習とモデル改善
データを基に異常検知モデルや予測モデルを精緻化し、より高精度な判断が可能になります。 - 自動化範囲の拡大
改善されたAIは、これまで人手が必要だった対応まで自律的に実施できるようになり、自動化領域が広がります。 - フィードバック
自動対応の結果や人間オペレーターの所見をデータとして再収集し、次のサイクルの学習に組み込みます。
このデータ→学習→実行→フィードバックのループにより、システムは経験から学び続けます。AmazonやTeslaがデータを糧に精度を高めてきたように、IT運用でも「使えば使うほど賢くなる運用」が実現するのです。最初は小さかった効果も、フライホイールが加速するごとに指数的な価値を生み出すでしょう。
「難しそうだ……自社に導入できるだろうか?」と感じる方もいるかもしれません。しかし心配は無用です。次章では90日で始めるための実践ステップを具体的に紹介します。ポイントを押さえて段階的に進めれば、思ったよりスムーズに自律運用への一歩を踏み出せるはずです。
第2章 90日クイックスタート戦略
「よし、AIOps×生成AIを導入しよう!」——そう決めたら、最初の90日間で何をすべきでしょうか。本章では0〜30日、31〜60日、61〜90日の3フェーズに分け、段階的に成果を出すロードマップを示します。短期間でPoC(概念実証)から本番展開まで走り切るための戦略です。
0〜30 日目:可観測性の強化とPoC準備
最初の1カ月は、AIOps導入の土台となる観測体制の強化に充てます。AIに任せるとはいえ、判断材料となるデータがなければ何も始まりません。次の3点を重点的にチェックしましょう。
- メトリクスとログの整備
システム健全性を測る主要メトリクス(CPU使用率、メモリ、レスポンス時間、エラー数など)が収集できているかを確認します。重要なアプリやサービスはダッシュボードにて一目で状態を把握できるようにし、監視が抜けている部分があればこの機会に追加します。分散システムであればトレーシングも有効です。ログは重要度に応じて集中管理(例:ELKスタックやクラウドのログ基盤)し、検索・分析しやすい状態にしておきましょう。データの「見える化」がAIOps成功の第一歩です。
- PoCシナリオの選定と評価指標の定義
小規模PoCでは、頻発するが自動化しやすいインシデントを1つ選ぶのがコツです。例として「メモリ逼迫によるサービス停止を検知して自動再起動する」あるいは「深夜バッチ処理失敗を自動復旧する」などが挙げられます。KPIも明確に設定し、MTTR(平均復旧時間)の短縮幅、アラート対応件数の削減率、誤報の減少率などを数値化しておきましょう。事前に成功基準を定義しておけば、後のROI算出がスムーズです。
- ツール選定と環境準備
PoCに用いるAIOpsツール(市販製品またはOSS)や生成AIモデルの利用方針(外部API利用かオンプレミス設置か)を検討します。小規模PoCならクラウドサービスの試用も有効です。ただし社内データを外部AIに送信する場合はセキュリティ承認が必要となることが多いため、早めに関係部門と調整しましょう。
この30日間で基盤固めと計画策定に集中すると、次フェーズで確実な成果を得る下地が整います。まさに「急がば回れ」です。
31〜60 日目:パイロット実装とROI測定
次の30日間では、限定範囲でパイロット(試行導入)を実施し、その効果を測定・検証します。
- 自動化の実装
PoCで選定した対象領域に自己修復フローを構築します。たとえばWebサービスAに対し「負荷急上昇 → スケールアウト」「メモリエラー検知 → プロセス再起動」「関連サービスの接続障害 → フェイルオーバー」といった定型アクションを自動化するイメージです。初めは冗長系サービスやステージング環境で試すとリスクを抑えられます。実システムでAIが自律判断・実行する体験をチーム全体で積むことが重要です。
- 効果測定とフィードバック
運用期間中に収集したデータを基に、当初設定したKPIでROIを算出します。MTTRの短縮幅、未然に防げたインシデント数、オペレーターの作業時間削減などを定量評価しましょう。
- 定量的成果の実証
例として「インシデント対応件数 50%減」「MTTR 35分短縮」といった結果が得られたとします。実際に、LogicMonitorは「統合ログ+メトリクス」でトラブルシューティングを最大80%高速化し、エンジニア工数を40%削減できたと説明しています(LogicMonitor, n.d.)。今回のパイロットでも同程度の改善が見られたなら、信頼性指標の大幅な向上=ROI向上が立証されたことになります。こうした数字はプロジェクト拡大の強力な後ろ盾となります。
成功も失敗も含め学びを蓄積し、うまく機能しなかった部分(誤検知や自動修復ミス)は原因を分析して改善策を講じましょう。
61〜90 日目:本番展開と体制強化
最後の30日間では、パイロット成果を踏まえて本番環境へ展開し、運用ガバナンスを確立します。
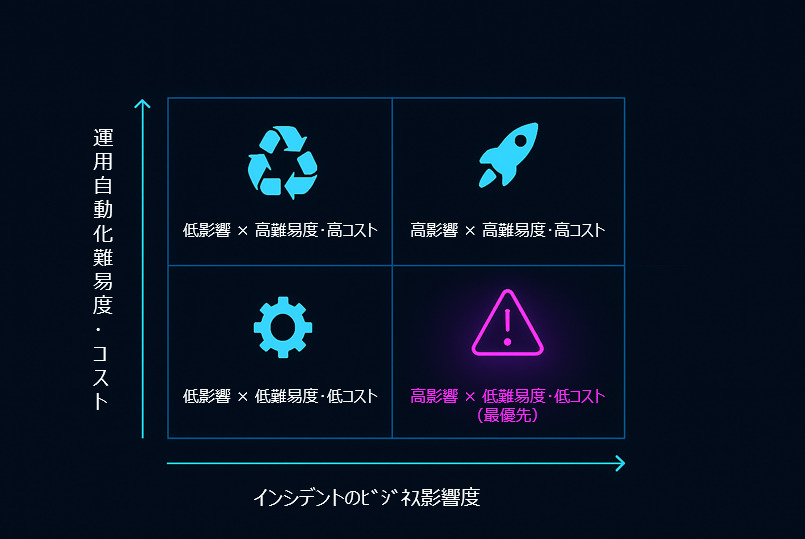
- 適用領域の選定
ROI評価マトリクスを活用すると取り組み優先度が可視化されます。横軸に「インシデントのビジネス影響度」、縦軸に「運用自動化難易度・コスト」をとり、「高影響 × 低難易度・低コスト」の領域を最優先で改善します。
- スケール展開と閾値チューニング
効果が高い領域から順次AIOpsを拡大適用します。運用が本番になると誤検知や過剰反応が顕在化しやすいので、異常検知モデルの閾値調整やフィルタリングルールの最適化をおこないましょう。LLMの応答も、パイロットの知見を基にプロンプト改善や知識ベース拡充を図ります。
- 成果サマリー作成と経営層レポート
90日目が近づいたら、技術詳細ではなくビジネスインパクトにフォーカスしたエグゼクティブサマリーを作成します。例えば、以下のようなものです。- 「月次○件の障害対応を削減し、運用部門の生産性が▲▲%向上」
- 「MTTR短縮により1回の障害あたり平均△万円の損失を回避」
BigPanda/EMA調査によれば、2024年時点の平均ダウンタイム損失は1分あたり14,056ドルに上昇していると報告されています(O’Connell, 2024)。数値で示すことで経営層の関心をつかみやすくなります。
- 運用フローと体制の見直し
「まずAIが対応し、失敗したら人間に通知」といった新しい自動化プロセスを手順書に明文化します。運用監視チーム向けにAI分析結果の読み解き方、プロンプト設計、過信を避ける判断力などを含むスキル研修を実施しましょう。人とAIのハイブリッド運用体制を整えることで、AIOpsの効果を最大化できます。
以上、3段階・90日間のクイックスタート戦略を述べました。小さく始めて成果を確認し、フィードバックを反映しながら段階的に拡大していくことで、社内の信頼を勝ち取りつつ次なる展開へとつなげましょう。
第3章 SRE 2.0とAIガバナンス
AIOps × 生成AIの導入は、技術面だけでなく人材の役割変革やガバナンス強化と表裏一体です。本章では、SRE(Site Reliability Engineer)の職務シフトと、AI活用に伴うリスク管理・コンプライアンスを考察します。技術と同じ重みでガバナンスを設計する──信頼できる自律運用には欠かせません。
SRE職務のシフト:単調作業削減 → ガードレール設計へ
「AIが運用を自動化したらSREの仕事は無くなるのか?」という疑問に答えるべく、本記事のテーマに踏み込みます。結論から言えば、SREの仕事は“なくなる”のではなく“進化する”と考えられます。確かにAIがアラート監視や一次対応といった単調作業を担えば、従来SREチームが費やしていた時間は大幅に削減されるでしょう。ある企業は「自動化により単調作業を減らし、エンジニアが高付加価値業務へ集中できる」と述べており、SREの役割はむしろ戦略的に拡大すると解説しています。
裏を返せば、人間のSREはより創造的で戦略的な役割へシフトします。キーワードはガードレール(Guardrails)の設計です。AIが自律的に動くとはいえ、すべてを丸投げにはできません。AIが暴走しない境界を定め、人間が安心して任せられる枠組みを作ることが新たなSREの重要任務です。
たとえば「本番DBを削除する操作はAIから実行しない」「深夜帯に顧客通知を送信する前に必ず人間の承認を要する」といったルールをPolicy‑as‑Codeで実装し、AIの行動を管理します。
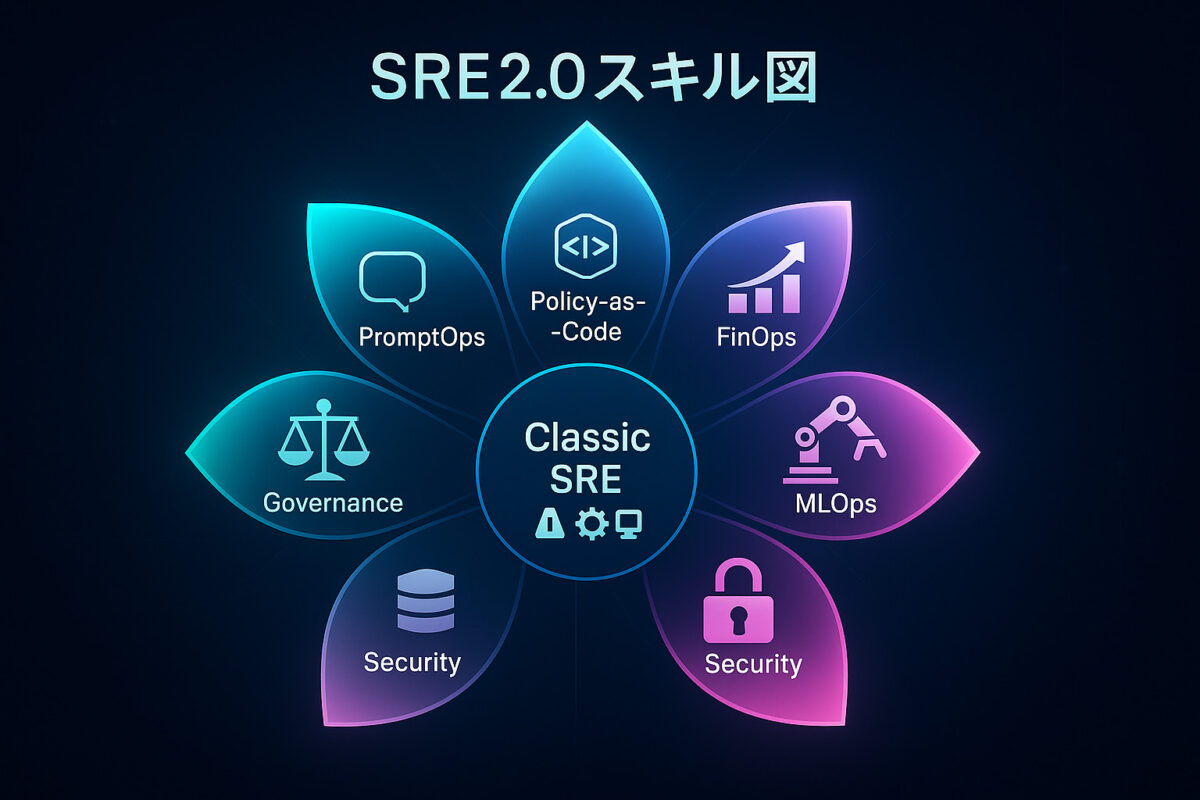
新たに求められる3つのスキル
- PromptOps(プロンプト・オプス)
LLM時代ならではのスキルであるプロンプトエンジニアリングです。運用現場では「このエラーの原因と推奨対処を100字で答えて」のように、問いの仕方しだいで得られる情報が変わります。AIを相棒として使いこなす対話術は、今後ますます重宝されるでしょう。
- Policy‑as‑Code(ポリシーのコード化)
運用ポリシーをコードで定義し、自動チェックと強制執行までおこなうスキルです。Open Policy AgentやAWS Configなどを用いてインフラ設定やAI挙動をリアルタイム監査し、違反時には自動修正・警告をします。
- FinOps(フィンオプス)
クラウド全盛の現在、コスト最適化は避けられません。LLMのAPI利用料や追加インフラ費用など、新たなコストを常に意識してROIを最大化する力が求められます。経営層に「いくら投資して何を節約できるか」を説明できることは大きな強みです。
これらに加えてMLOpsやセキュリティ知識も重要度を増します。総じて言えば、「SRE 2.0」はテクノロジーと戦略の橋渡し役です。現場の泥臭い作業から解放された分、SREはシステム全体を見渡し、AIと人間の協調体制を設計するアーキテクトへと進化します。言わば「AI運用オーケストラの指揮者」となり、各パート(AIエージェント、人、プロセス)が調和して信頼性という音楽を奏でるよう指揮していくのです。
なお、AIによる自動化が進むほど人間の介在機会は減りますが“ゼロ”にはなりません。むしろ人間にしかできない判断や創造が際立つ局面が現れます。SRE2.0を生きるエンジニアは、こうした高次の役割で価値を発揮できるようスキルとマインドをアップデートしていきましょう。
リスク管理とコンプライアンス:AI運用のチェックポイント
AIOps × 生成AIを導入する際はリスクとコンプライアンスへの配慮も不可欠です。便利さの裏に潜む落とし穴を見逃さず、責任あるAI運用を実現するポイントを整理します。
- ハルシネーション(幻覚)対策
生成AI(LLM)は、ときに事実と異なる回答をもっともらしく作り上げてしまいます。運用現場で誤った原因分析や不適切な対処を招かないよう、Human in the Loopを維持し、重要な決定は必ず人間が確認するルールを設けましょう。加えて、プロンプトの範囲を限定し、出力に信頼度スコアを付与するなどの工夫も有効です。さらにRAG(Retrieval‑Augmented Generation)を活用し、社内ナレッジを参照させることで幻覚リスクを大幅に低減できます。 - セキュアなRAGで社内データを守る
社内の機密ログや設定情報をそのままクラウドLLMに送信すると、情報漏えいの恐れがあります。オンプレミスでLLMを運用する、送信データをマスキング/暗号化する、プロンプトと応答をログで監視する──など、多層的なセキュリティアーキテクチャを構築しましょう。アクセス制御を徹底し、AIには最小権限だけを付与することが肝要です。 - 責任あるAI運用のチェックリスト
- 責任の所在を明確にする(例:SREマネージャーやプロダクトオーナー)
- 透明性と説明性を確保:AIの判断根拠をログに残し、後からレビューできる状態にする
- 定期的なモデル評価とバイアスチェックをおこない、必要に応じて再学習・アップデート
- AI倫理委員会など横断チームによるガバナンス体制を整備
- フェールセーフとバックアップを用意し、AI任せにしすぎない安全弁を確保
以上の対策を講じることで、テクノロジー面の導入効果とガバナンス面の強化が両立し、真に信頼できるAIOpsが実現します。Red Hatによるポリシー自動化フレームワークなど、企業支援ソリューションも続々登場しています(Red Hat, 2022)。
第2章までで築いた技術的基盤に、本章で述べた人とプロセスのガバナンスを組み合わせれば、鬼に金棒ならぬ「AIに金棒」の盤石な自律運用体制が整うでしょう。
終章 人間中心の自律運用へ
最後に、本記事のポイントを振り返りながら、これから皆さまが取るべきアクションを提案します。
AIOps × 生成AI がもたらす3つの主なメリット
- MTTRの大幅な短縮
アラートの自動相関とAI解析により、障害対応の速度が飛躍的に向上し、システム停止時間を最小化できます。AI導入によって平均復旧時間が65分から10分へ短縮した事例も報告されています(Netka System, 2025)。ただし、同社ブログによる自社事例で、第三者検証は未公開になります。ダウンタイムの削減は、顧客満足度と収益保護に直結します。 - 人的リソースの高度化と有効活用
定型業務をAIが肩代わりすることで、エンジニアは創造的かつ付加価値の高い業務に集中できます。夜間対応が減れば疲弊も抑えられ、人材定着率や士気の向上にもつながります。言い換えれば、自動化によって人間本来の強みが発揮できる環境が整うのです。 - 運用ROIの向上
信頼性指標の改善と障害損失の低減により、投資対効果が明確にプラスとなります。たとえば、1分の停止で数百万円の損失が発生するケースでも、AIがそれを防ぐことで確実なコスト削減が期待できます。さらに、省人化による運用コストの圧縮や、サービス品質向上による売上増など、多面的なROI向上効果が得られます。
これらのメリットを踏まえれば、AIOps × 生成AIはもはや単なる流行語ではなく、競争力強化の必須ピースと言えるでしょう。重要なのは「AIが人間を排除する」のではなく、「AIが舞台装置となり、人間(SRE)が演出家として全体を掌握する」関係を築くことです。人間中心の視点を忘れずテクノロジーを使いこなしてこそ、持続的な成功が得られます。
幸い、初期導入を後押しするリソースは増えています。まずは行動を起こしましょう。未知の領域に踏み出す不安はあるかもしれませんが、本記事で描いたストーリーのように、一歩踏み出せば未来の運用風景は大きく変わります。
ぜひ貴社も次の主役となるべく、この機会に自律運用への第一歩を踏み出してください。現場の悲鳴を歓喜に変える挑戦を、私たちも全力でサポートいたします。共に、人間中心の自律運用という新しいステージへ進みましょう!
参考文献
- Gartner. (2016, December 19). AIOps (artificial intelligence for IT operations). Gartner IT Glossary. https://www.gartner.com/en/information-technology/glossary/aiops-artificial-intelligence-operations
- LogicMonitor. (n.d.). Reduce MTTR with unified logs and metrics. Retrieved July 16, 2025, from https://www.logicmonitor.com/reduce-mttr
- Netka System. (2025). Integrating AIOps with ITSM tools: Streamlining incident management like never before. Retrieved July 16, 2025, from https://netkasystem.com/integrating-aiops-with-itsm-tools-streamlining-incident-management-like-never-before/
- O’Connell, V. (2024, April). IT outages: 2024 costs and containment. Enterprise Management Associates. https://www.bigpanda.io/wp-content/uploads/2024/04/EMA-BigPanda-final-Outage-eBook.pdf
- Poda, M. (2025, April 11). Mission: AI Possible—What agentic AI means for the future of ITOps. LogicMonitor. https://www.logicmonitor.com/blog/decoding-agentic-ai-for-itops-excellence-with-openai-and-devoteam
- Red Hat. (2022, December 16). Introduction to policy as code with automation [Blog post]. Red Hat. https://www.redhat.com/en/blog/policy-as-code-automation
- Veeam Software. (2020, June 2). CXO research: Legacy technology and lack of skills hindering digital transformation and IT modernization [Press release]. https://www.veeam.com/company/press-release/cxo-research-legacy-technology-and-lack-of-skills-hindering-digital-transformation-and-it-modernization.html

